一般來說,針對 Machine Learning workflow 有幾個大方向的建議:
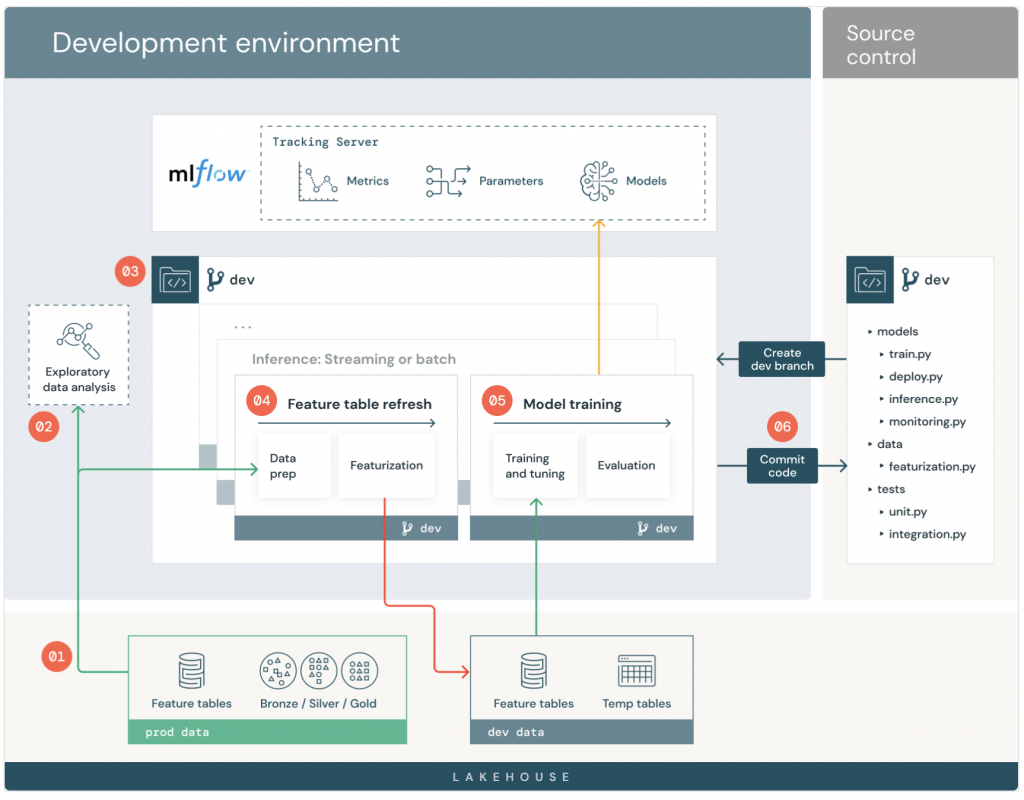
以下針對 Development stage 的重點部分作說明。
The focus of the development stage is experimentation. Data scientists develop features and models and run experiments to optimize model performance. The output of the development process is ML pipeline code that can include feature computation, model training, inference, and monitoring.
以中文來說,Development stage 的重點在於實驗。資料科學家會開發特徵與模型,並且透過實驗來優化模型的效能。開發的結果會是一個 ML pipeline 的程式碼,包含了特徵計算、模型訓練、推論與監控。
資料科學家在開發環境通常只有唯讀的存取權限。為了符合資料治理的需求,有些特殊情形之下,開發環境可能可以存取到 Production 環境的 Mirror 版本,或是經過刪減的版本。
Exploratory data analysis (EDA)
Code
就是資料科學家的開發階段與相關的程式碼。
Update feature tables
The model development pipeline reads from both raw data tables and existing feature tables, and writes to tables in the Feature Store.
中文來說明上述的部分,就是機器模型的開發 pipline 是從 Raw data 與 Feature 讀取資料,並且將結果寫入 Feature Store。
Train model
Commit code
下一篇會介紹 Staging stage 的部分。
Refernce: https://docs.databricks.com/en/machine-learning/mlops/mlops-workflow.html

